 掃一掃
掃一掃智慧安全風險管控軟件平臺軟件設計方案
來源: 時間:2025-30-9 瀏覽次數:0次
一.項目背景
智慧安全風險管理平臺對風險隱患實施清單化管理,逐個劃定風險等級,明確主體、屬地、行業、綜合監管部門職責,打造各負其責的管理模式,通過數字化手段重塑閉環管理流程;通過智慧安全風險管理平臺多源數據整合,以及各類風險隱患判定標準及準則、應急管理法律法規、各行業領域安全管理辦法和規章制度,鹽田區積極探索并應用生成式大模型技術,建立風險隱患智能體,旨在準確理解用戶查詢意圖和關鍵詞,提供精準的風險隱患信息檢索反饋。同時,基于用戶的歷史查詢行為和當前查詢內容,智能推薦相關風險隱患查詢結果,提升用戶體驗。一線工作人員通過交互式提問,AI智能檢索相關資料并提出專業回答,使得每位工作人員都能夠快速掌握工作業務標準,正確判斷隱患處理流程,精準識別隱患現狀。
二.總體架構
智慧安全風險管理平臺置入風險隱患上報、專業復核、工作建檔、日常巡查、智能監測、隱患核銷等多項功能,對風險隱患實施清單化管理,逐個劃定風險等級,明確主體、屬地、行業、綜合監管部門職責,打造各負其責的管理模式,通過數字化手段重塑閉環管理流程。
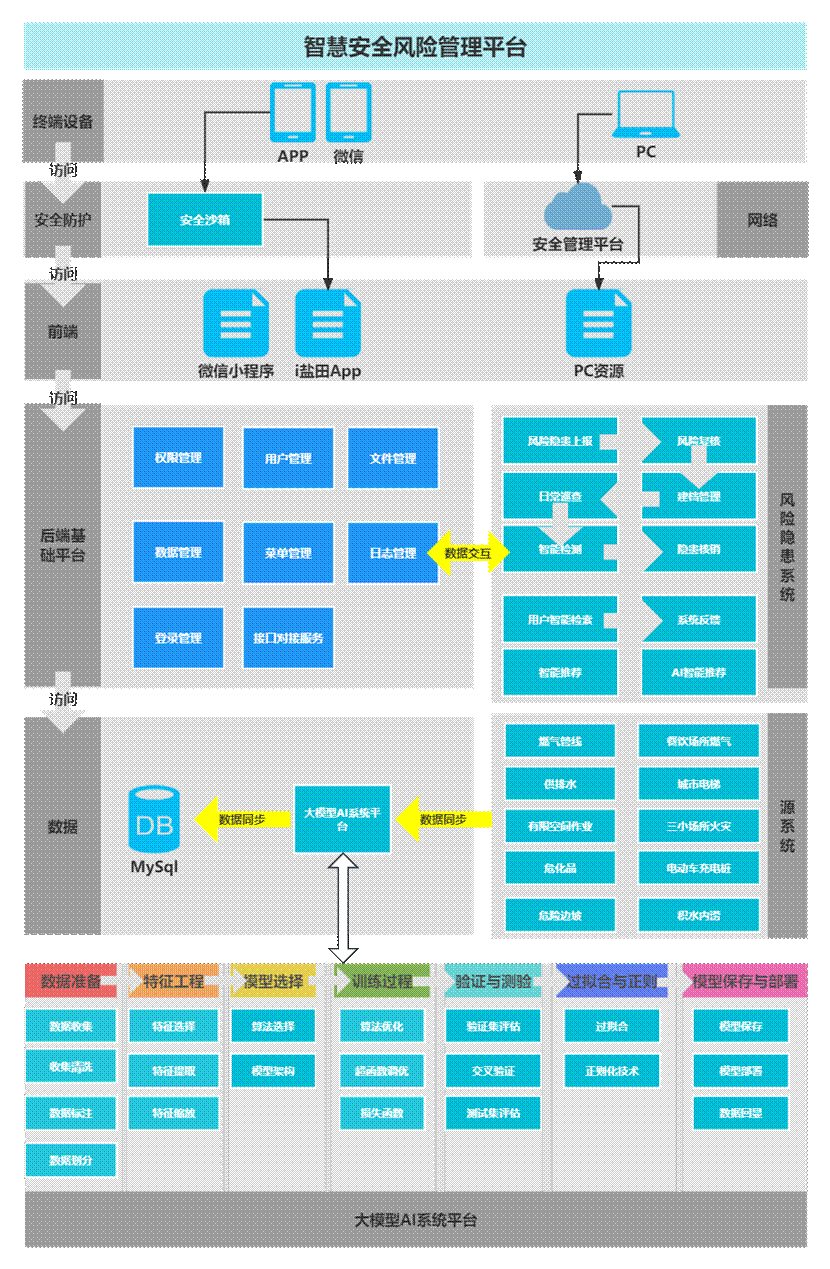
三.技術機構
四.功能設計
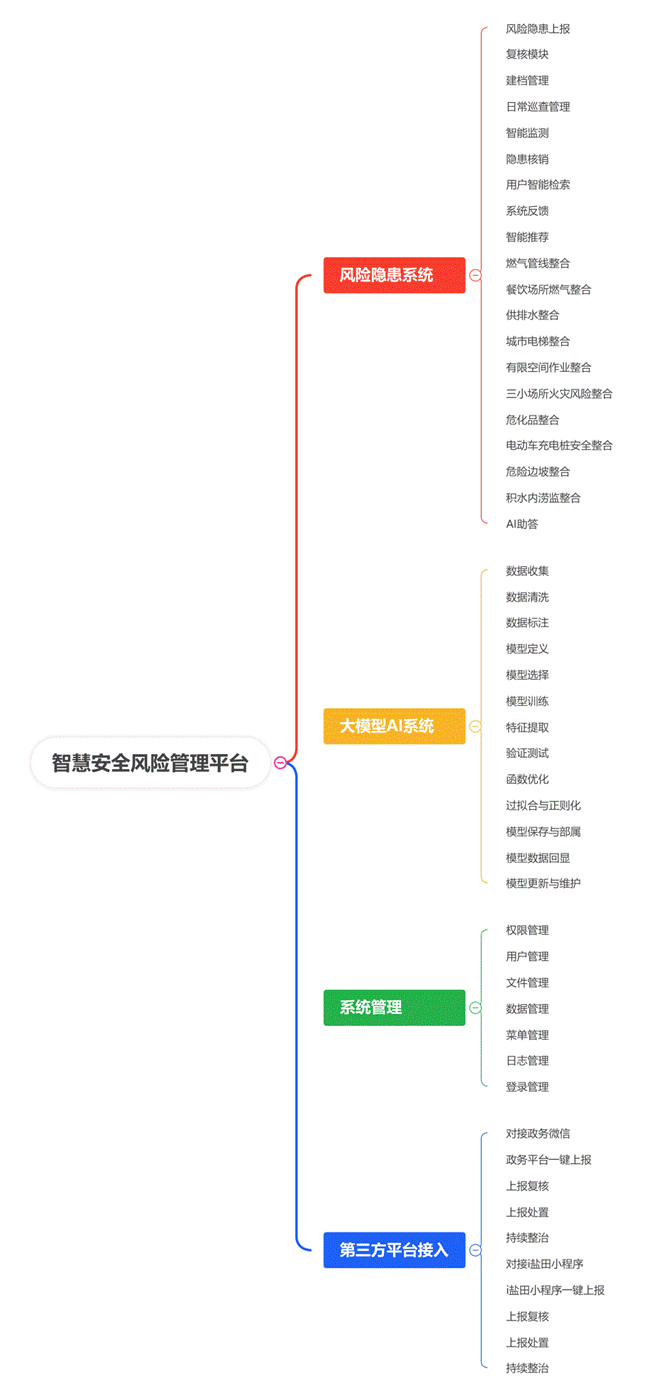
本平臺由風險隱患系統、大模型AI系統、系統管理、第三方平臺接入四大模塊組成。詳情見下圖:
4.1風險隱患系統
風險隱患系統包含風險管理體系(風險隱患上報、復核模塊、建檔管理、日常巡查管理、智能監測、隱患核銷)、AI智能答疑(用戶智能檢索、系統反饋、智能推薦、AI助答)、數據整合(燃氣管線整合、餐飲場所燃氣整合、供排水整合、城市電梯整合、有限空間作業整合、三小場所火災風險整合、危化品整合、電動車充電樁安全整合、危險邊坡整合、積水內澇監整合)等內容。
4.1.1風險管理體系
風險管理體系是指為上報、識別、評估、控制和監測風險而建立的一整套制度、流程。它的目的是幫助組織有效管理風險,以實現其戰略目標、保護資產、確保合規并提升決策的有效性。
風險隱患上報:包含基本信息:上報單位、上報人姓名及聯系方式、上報日期等;隱患詳細信息:隱患名稱隱患類型(如設備故障、環境安全、操作不當等)具體位置(如車間、設備、區域等)隱患描述(詳細說明隱患的性質、原因和可能導致的后果)。
風險復核:風險復核是風險管理過程中的一個重要環節,旨在對已識別和評估的風險進行重新審查和驗證,以確保風險信息的準確性、完整性和時效性。通過風險復核,組織能夠及時調整風險管理策略,確保有效應對潛在風險。
復核內容包含基本信息確確認、風險準確性、是否有新風險、風險影像程度、更新風險等級。
建檔管理:建檔管理是指對組織內部各種風險檔案、風險文檔和記錄進行系統化、規范化的管理,以確保信息的完整性、準確性和可追溯性。規范化的建檔管理不僅有助于提高工作效率,還能增強組織的合規性和風險管理能力。
建檔管理中對風險基本信息、風險等級、風險類型、風險圖片、應答信息、處理方案等內容做長期的保存,防止信息丟失,為以后的決策提供參考。
日常巡查管理:日常巡查管理是指在企業或組織的日常運營中,對各項工作、設施、環境、設備等進行定期或不定期的檢查和監督,以確保其正常運轉、符合安全標準和管理規范。日常巡查管理有助于及時發現問題、預防事故、提高工作效率和保障安全。
依據巡查計劃、定期或不定期進行巡查、檢查現場情況、對巡查中的問題以及結果進行整改和記錄,對已出現的問題進行跟蹤和反饋。
智能檢測:通過大數據智能檢測災情技術結合了大數據分析、人工智能和物聯網等先進技術能夠顯著提升災情監測和響應的效率。實時監測(通過傳感器和監測設備,能夠實時收集環境數據,及時發現潛在的災害風險,數據可以實時更新,確保監測信息的及時性和準確性)精準分析(利用大數據分析技術,可以從大量數據中提取有價值的信息,識別災害模式和趨勢、通過機器學習和預測模型,可以分析歷史數據,預測未來可能發生的災害,提前做好準備)提高響應效率(系統可以根據設定的閾值自動發出警報,減少人工干預,提高響應速度,通過數據分析,可以更有效地分配救援資源,提高應急響應的效率)多源數據整合(可以整合來自不同來源的數據(如氣象數據、地理信息、社交媒體等),提供全面的災情視圖,促進各部門之間的信息共享與協作,提高整體應急管理能力)增強決策支持(基于數據分析的結果,決策者可以做出更科學、合理的決策,通過數據可視化技術,將復雜數據以圖表或地圖的形式展示,便于理解和分析)降低經濟損失(通過及時發現和預測災情,可以減少災害造成的經濟損失和人員傷亡,大數據分析可以幫助評估不同災害的風險,制定相應的防范措施,降低潛在損失)。
隱患核銷:隱患核銷是指在安全管理和風險控制過程中,對已識別的安全隱患進行整改、消除或控制后,進行的確認和記錄,以確保隱患得到了有效處理。這一過程通常包括隱患的識別、整改措施的實施、效果的驗證以及最終的核銷,旨在提升安全管理水平,減少事故發生的可能性。
4.1.2 AI智能答疑
AI智能答疑模塊包含:用戶智能檢索、系統反饋、智能推薦、AI助答等內容。
用戶智能檢索:用戶智能檢索是指利用人工智能技術,特別是自然語言處理(NLP)和機器學習,來幫助用戶更高效地查找和獲取所需信息的系統或工具。它通過理解用戶的查詢意圖,提供更精準和相關的搜索結果。
用戶通過文本輸入查詢,系統對輸入進行預處理,包括分詞、去除停用詞、語法分析,從知識庫、數據庫或互聯網中檢索相關信息,使用排名算法對結果進行排序,將檢索到的信息以文本、圖像、視頻等多種形式呈現。
系統反饋:系統智能反饋是利用AI技術自動處理用戶反饋信息,從中提取有價值的見解,并根據這些見解調整系統行為。通過用戶交互、調查問卷、評論和評分等多種方式收集用戶反饋,識別用戶的主要需求、問題和建議,評估反饋的情感傾向(積極、消極或中立),根據分析結果,系統可以自動生成響應,或者將重要信息反饋給詢問人員。
智能推薦: 智能推薦是通過分析用戶的歷史行為和偏好,結合其他用戶的數據,自動生成個性化推薦結果的過程。本系統即可基于相似用戶的行為進行推薦,也可基于相似搜索的行為進行推薦。
AI助答:AI助答是通過人工智能算法,自動理解用戶提出的問題,并生成相應的回答或建議的過程,用戶通過文本方式輸入問題,系統首先對輸入進行預處理,包括分詞、搜索等,利用自然語言處理技術,系統分析用戶的輸入,識別用戶的意圖和需求。這一過程可能涉及分類算法、關鍵詞提取等。根據識別出的意圖,系統從知識庫、FAQ、數據庫或互聯網中檢索相關信息,在獲取相關信息后,系統生成回答。回答是基于上下文生成的自然語言文本。
4.1.3 數據整合
數據整合包含(燃氣管線整合、餐飲場所燃氣整合、供排水整合、城市電梯整合、有限空間作業整合、三小場所火災風險整合、危化品整合、電動車充電樁安全整合、危險邊坡整合、積水內澇監整合)等內容。
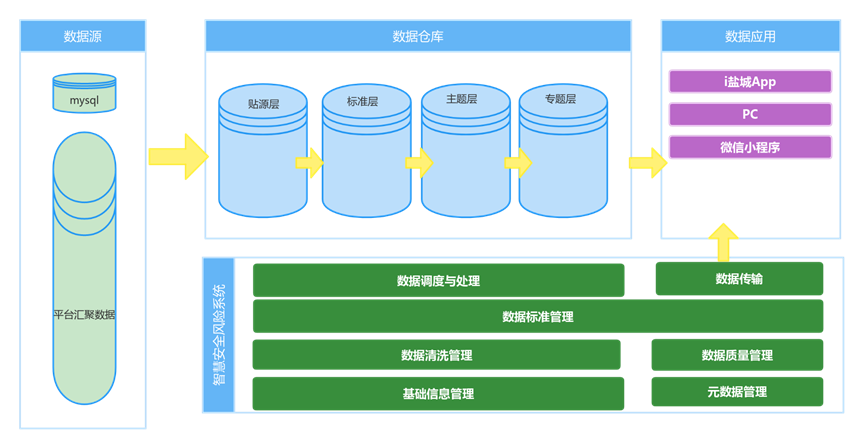
將平臺中收集到的的燃氣管線、餐飲場所燃氣、供排水、城市電梯、有限空間作業、三小場所火災風險、危化品、電動車充電樁安全、危險邊坡、積水內澇監的數據進行清洗,去除重復、錯誤或不完整的數據,確保數據的質量和一致性,然后將不同格式、結構和類型的數據進行轉換,以便于整合。將清洗和轉換后的數據進行整合,采用數據倉庫的方式,將數據存儲在一個集中數據庫中。最后對整合后的數據進行驗證,確保數據的準確性和完整性,消除潛在的錯誤。將整理后的數據進行訓練或回顯到界面中。
4.2大模型AI系統
大模型AI系統包含數據準備、特征工程、模型選擇、訓練過程、驗證與測試、過擬合與正則、模型保存與部署七個步驟;
4.2.1數據準備
模型訓練數據準備是構建有效機器學習模型的關鍵步驟之一。良好的數據準備不僅能提高模型的性能,還能確保模型的泛化能力和可靠性。
數據收集:明確項目目標和任務類型,根據任務需求確定需要收集的數據類型,利用已有的公開數據集,從公司現有的數據庫、平臺系統獲取數據,通過交叉驗證的方式確保數據在不同來源和格式之間的一致性,確保收集的數據完整,避免缺失值過多。
數據清洗:數據清洗是數據預處理過程中的一個重要環節,旨在提高數據質量,為后續分析和建模提供可靠的基礎,首先對數據集進行初步審查,了解數據的結構、類型、分布情況等,使用統計方法(如均值、方差、最小值、最大值等)對數據進行描述,識別潛在問題,識別數據集中是否存在重復的記錄,根據業務需求選擇保留哪條記錄,選擇保留第一次出現的記錄,或根據其最新時間進行選擇。識別數據集中缺失值的數量和位置,使用數據框架的內置函數的isnull()來檢查,刪除包含缺失值的記錄或特征,確保每列數據的類型正確,將分類變量轉換為數值型變量。
數據標注:數據標注是指為數據集中的每個數據樣本分配標簽或注釋的過程。這些標簽可以是類別、屬性、描述或其他形式的標識,具體取決于任務的需求。
數據標注中將數據樣本分配到預定義的類別中,可將數據樣本分配一個連續值,也可對序列中的每個元素進行標注,為文本數據中的特定部分添加標簽,由操作人員進行標注并對對標注結果進行審核和驗證,確保標注的準確性和一致性。將標注結果存儲在數據庫中,以便后續使用和分析。
.2.2特征工程
特征選擇:特征選擇是機器學習和數據挖掘中的一個重要步驟,旨在從原始特征集中選擇出對模型預測最有用的特征。有效的特征選擇不僅可以提高模型的性能,還可以減少計算成本、降低過擬合的風險,并提高模型的可解釋性。
特征提取:特征提取是指從原始數據中轉換或提取出有意義的特征,以便用于機器學習模型的訓練。特征可以是原始數據的某種變換、組合或統計量,目的是將數據的維度降低,同時保留對任務有用的信息。本系統通過提取文本特征TF-IDF、詞嵌入來進行語境分析。
4.2.3模型選擇
算法選擇:本系統在不同的環境中采用不同的算法包括:分類算法將數據分類到預定義的類別中,回歸算法:用于預測連續值。聚類算法:用于將數據分組降維算法:用于減少特征數量,同時保留數據的主要結構,使用協同過濾、矩陣分解等算法分析用戶行為,提供個性化推薦。使用深度學習模型BERT進行文本分類、情感分析等。
模型架構:模型架構是指機器學習模型的結構和組成部分,包括輸入層、隱藏層、輸出層以及它們之間的連接方式。好的模型架構能夠有效地捕捉數據中的模式和特征,從而提高預測或分類的準確性。本系統采用決策樹和集成模型。
決策樹是一種基于樹形結構的模型,通過一系列的決策規則將數據分割成不同的類別或預測值。每個節點表示一個特征的測試,每個分支表示測試的結果,每個葉子節點表示最終的分類或回歸結果。
集成模型是將多個基學習器(如決策樹)組合在一起,以提高整體模型的性能。集成學習的基本思想是通過結合多個模型的預測結果來減少偏差和方差,從而提高準確性和魯棒性。
4.2.4訓練過程
初始化模型參數,例如權重和偏置。對于深度學習模型,通常使用隨機初始化或特定的初始化方法(如He或Xavier初始化)。
將訓練數據輸入模型,計算輸出結果。對于神經網絡,這涉及到通過每一層進行計算,最終得到預測值。
使用損失函數計算模型預測值與真實值之間的差異。常見的損失函數有:
回歸任務:均方誤差(MSE)、平均絕對誤差(MAE)。
分類任務:交叉熵損失Cross-Entropy Loss。
通過反向傳播算法計算損失函數對模型參數的梯度。該步驟通常使用鏈式法則來計算每一層的梯度。
使用優化算法隨機梯度下降Adam根據計算出的梯度更新模型參數,以最小化損失函數。
4.2.5驗證與測試
驗證:驗證是對模型在訓練過程中進行評估的過程,旨在監控模型的性能,幫助進行超參數調優和選擇最優模型。驗證集是從訓練集中分離出來的數據,用于評估模型的泛化能力。
將訓練集劃分為K個子集,輪流將每個子集作為驗證集,其他K-1個子集作為訓練集,最終計算K次驗證結果的平均值。簡單地將訓練集劃分為訓練集和驗證集,采用80/20或70/30的比例。
測試:測試是對模型在未見數據上的性能進行評估的過程。測試集是從整個數據集中分離出來的數據,模型在訓練和驗證過程中不會接觸到這些數據。
在模型訓練和驗證完成后,使用測試集對模型進行評估,計算模型的性能指標。測試結果是報告給利益相關者,以便做出決策(如部署模型)。
與驗證階段相同,依據任務的性質選擇相應的評估指標。測試集的評估結果被視為模型的最終性能。
4.2.6過擬合與正則
過擬合:過擬合是指模型在訓練數據上表現得很好,但在未見數據(如驗證集或測試集)上表現較差的現象。換句話說,模型過于復雜,以至于捕捉到了訓練數據中的噪聲和偶然性,而不是學習到數據的真實分布。
產生原因模型復雜度過高:模型的參數數量遠大于訓練樣本數量。訓練數據不足:訓練數據量小,不能有效代表真實數據分布。噪聲數據:訓練數據中包含了很多噪聲和異常值。
正則化:正則化是一種防止過擬合的方法,通過在損失函數中添加額外的約束項來限制模型的復雜度。常見的正則化方法包括:
L1 正則化(Lasso Regularization)
定義:在損失函數中添加參數絕對值之和的懲罰項。
公式:L=Loriginal+λ∑∣wi∣L=Loriginal?+λ∑∣wi?∣
特點:可以導致一些權重變為零,從而實現特征選擇。有助于提高模型的可解釋性。
L2 正則化(Ridge Regularization)
定義:在損失函數中添加參數平方和的懲罰項。
公式:L=Loriginal+λ∑wi2L=Loriginal?+λ∑wi2?
特點:不會使權重變為零,而是會使權重變小。有助于減少模型的復雜度,防止過擬合。
3. Dropout
定義:在訓練過程中隨機丟棄一部分神經元,以減少神經元之間的相互依賴。
特點:有效防止過擬合,尤其是在深度學習模型中。訓練時以一定概率忽略某些神經元,測試時使用所有神經元。
4. 提前停止(Early Stopping)
定義:在驗證集性能不再提升時停止訓練。
特點:防止模型在訓練集上過擬合。監控驗證集的損失或準確率,在達到最佳性能時停止訓練。
5. 數據增強
定義:通過對訓練數據進行變換(如旋轉、縮放、翻轉等)來生成更多的訓練樣本。
特點:增加訓練數據的多樣性,幫助模型更好地泛化。
4.2.7模型保存與部署
模型保存包含:模型結構(模型的架構信息,層的類型、層的數量、激活函數等)、模型權重:(訓練過程中學習到的參數(權重和偏置)、優化器狀態(可選):如果需要繼續訓練,保存優化器的狀態(如學習率、動量等)也是有用的。
部署流程包含:模型導出(將訓練好的模型導出為適合部署的格式ONNX、TensorFlow SavedModel等)、選擇部署平臺:(根據應用需求選擇合適的服務器或云平臺)、搭建服務(使用API FastAPI或微服務架構Docker、搭建服務,使模型能夠接收請求并返回預測結果)、監控與維護(部署后需要監控模型的性能,并根據需要進行更新和維護)。
4.3系統管理
系統管理包含權限管理、用戶管理、文件管理、數據管理、菜單管理、日志管理、登錄管理等內容。
4.3.1權限管理
權限管理是確保系統安全可靠運行的重要組成部分。
對于服務器、控制臺和其他關鍵設備,必須實施嚴格的訪問控制措施,限制只有授權人員才能夠訪問系統。訪問控制通過身份驗證和授權機制來實現,使用用戶名和密碼、雙因素認證等方式。不同的用戶需要不同級別的權限來執行不同的操作。因此,需要實施權限分級制度,確保每個用戶只能訪問其所需的功能和數據。管理員具有最高級別的權限,可以對系統進行全面管理和配置。系統記錄所有用戶的操作,包括登錄、修改配置、更新信息等,以便進行審計和追蹤。審計日志應該具有不可篡改性,并且只有授權人員才能夠查看和管理。對于關鍵設備和系統組件,應該實施實時監控,及時發現異常情況并采取相應的措施。實時監控可以包括對網絡流量、服務器負載、傳感器數據等的監測。需要定期對權限管理策略進行審查和更新,確保其與實際需求和最佳實踐保持一致。定期審查幫助發現和糾正潛在的安全風險和漏洞。在發生安全事件或緊急情況時,有相應的應急措施和流程,以最大程度地減少損失并迅速恢復系統功能。應急措施可能包括備份恢復、臨時訪問權限調整等。
4.3.2用戶管理
用戶管理是指對用戶賬戶信息進行管理和控制的一系列功能,包括添加、修改、刪除、查詢用戶以及設置管理權限等。其主要目的是確保系統的安全性和可用性,滿足不同用戶的需求。
用戶管理的基本功能:
添加用戶:向用戶表或用戶信息庫中增加用戶信息,建立新用戶。
修改用戶:修改已有用戶的信息,如更改用戶名、密碼或分配權限等。
刪除用戶:從用戶表或用戶信息庫中刪除用戶信息,注銷已有用戶。
查詢用戶:查詢用戶表或用戶信息庫中的用戶信息,了解哪些用戶存在及其信息。
設置權限:設置用戶的登錄權限和操作功能的權限,以控制系統訪問。
4.3.3文件管理
文件管理是操作系統的一項重要功能,主要涉及文件的邏輯組織和物理組織、目錄的結構和管理。文件管理是通過一組軟件來實現的,這些軟件負責存取和管理文件信息。從系統角度來看,文件系統是對文件存儲器的存儲空間進行組織、分配和回收,負責文件的存儲、檢索、共享和保護。從用戶角度來看,文件系統實現了“按名取存”,用戶只需知道文件名即可存取文件中的信息,而無需知道文件的具體存儲位置。
4.3.4數據管理
數據管理是指對數據的收集、存儲、處理、分析和維護等一系列活動的系統性管理,以確保數據的準確性、安全性和可用性。有效的數據管理能夠幫助組織更好地利用數據資源,支持決策制定和業務發展。
- 數據處理:包括從其他數據源中提取原始數據,通過數據集成技術處理或加載數據,進行過濾、合并或聚合,滿足特定的需求,本系統采用預測性機器學習算法。
- 數據存儲:根據數據的類型和用途選擇合適的存儲庫,數據倉庫需要定義的模式來滿足特定的數據分析需求。數據的存儲由業務用戶與數據工程師合作指導和記錄。
- 數據安全:確保數據的安全性,防止數據泄露和未經授權的訪問,保護個人身份信息(PII)等敏感數據。
- 數據質量:確保數據的準確性、完整性和一致性,避免因數據錯誤導致的決策失誤。
4.3.5菜單管理
軟件菜單管理是指在軟件應用程序中設計、實現和維護用戶界面菜單的過程。菜單是用戶與軟件交互的重要組成部分,良好的菜單管理可以提高用戶體驗和軟件的易用性。
菜單管理的基本功能和操作:
- 新增菜單:操作人員通過點擊“新增”按鈕來實現增加新的菜單項。
- 刪除菜單:選擇需要刪除的菜單項,點擊“刪除”按鈕進行刪除操作。
- 生成WAP頁面:本功能為手機端生成主頁,方便移動設備訪問。
- 修改菜單屬性:操作人員可以對菜單的名稱、排序、圖標等進行修改,以適應不同的使用場景。
- 授權管理:操作人員可以為不同的用戶或角色分配不同的權限,如增刪改查、導出等權限。
- 排序:操作人員可以通過修改排序字段進行菜單的排序。排序后菜單內容由排序字段由小到大一次排列。
- 圖標設置:操作人員可以為菜單設置圖標,用于快速識別和精準訪問。
4.3.6日志管理
日志是系統或應用程序在運行過程中記錄的事件信息。這些信息通常包括時間戳、事件類型、事件級別、消息內容和其他相關數據。日志可以幫助用戶了解系統的行為和狀態。
本系統日志管理包含訪問地址、參數、訪問ip、時間、用戶、類型、安全事件、安全信息、操作等內容。用戶可以根據IP地址、選擇用戶、開始時間、結束時間檢索自己想要的內容。超級管理員也可點擊清空日志將所有的日志內容清空。
4.3.7登錄管理
登錄管理是指對用戶身份驗證和授權過程的管理,以確保只有經過授權的用戶才能訪問系統或應用程序的功能和數據。有效的登錄管理不僅可以提高系統的安全性,還能提升用戶體驗。
本系統采用用戶名和密碼登錄:用戶輸入唯一的用戶名和密碼進行身份驗證。
密碼應采用安全的存儲方式(如哈希和鹽)以防止泄露。
本系統登錄流程:
用戶打開登錄頁面:用戶訪問智慧安全風險平臺登錄頁面,頁面包含用戶名輸入字段和密碼輸入字段,以及登錄按鈕。
用戶輸入憑據:用戶在登錄頁面上輸入其已注冊的用戶名和相應的密碼。
客戶端驗證:用戶點擊登錄按鈕后,客戶端會對輸入的憑據進行驗證,包括格式驗證和空值檢查。
憑據傳輸:客戶端使用安全的方式將用戶輸入的憑據發送到服務器端。
服務器端驗證:服務器端接收到用戶登錄請求后,進行進一步驗證,包括用戶名存在性驗證和密碼哈希值比對。
生成登錄令牌:如果憑據驗證成功,服務器會生成一個登錄令牌,并將其發送回客戶端。
會話管理:客戶端存儲登錄令牌,后續請求攜帶該令牌以驗證用戶身份。
登錄成功:服務器設置登錄狀態為已認證,并重定向用戶到特定頁面。
登出處理:用戶點擊登出按鈕或會話過期時,客戶端發送登出請求,服務器重置登錄狀態并刪除令牌。
4.4第三方平臺接入
第三方平臺接入是指將外部服務或應用程序與自己的系統進行集成,以實現數據共享、功能擴展或用戶體驗提升。通過接入第三方平臺,企業可以利用已有的技術和服務,減少開發成本和時間,提高系統的靈活性和可擴展性。本系統中接入微信小程序和“i鹽城”APP實現一鍵上報和人員的跟蹤操作。
4.4.1微信小程序接入
注冊與認證:首先,開發者需要在[微信公眾平臺]注冊一個小程序賬號,并完成相關認證。認證過程中,需提供企業或個人相關資質,確保賬號的合法性和安全性。
開發環境搭建:完成注冊后,開發者需下載并安裝[微信開發者工具]。該工具提供了代碼編輯、調試、預覽等功能,是小程序開發的重要輔助工具。
創建與配置小程序:在UDSO低代碼開發平臺中點擊終端管理選擇微信小程序點擊添加按鈕填寫自己的信息并生成對應代碼,將平臺生成的代碼導入到終端管理工具中,配置服務器域名。
開發與調試:進入開發階段,開發者需根據微信小程序的開發規范,編寫前端和后端代碼。同時將一鍵上報、上報復核、上報處置、持續整治等內容編寫到程序中,利用微信開發者工具進行代碼調試和功能測試,確保小程序的穩定性和可用性。
上傳與審核:完成開發和調試后,開發者需將小程序代碼上傳至微信服務器進行審核。審核通過后,小程序即可正式發布上線,供用戶使用。
五.方案下載
《智慧安全風險管控軟件平臺軟件設計方案》,點擊下載
- 上一篇: 社會救助經辦服務軟件系統解決方案
- 下一篇: 沒有了