 掃一掃
掃一掃
服務近2000家企業,依托一系列實踐中打磨過的技術和產品,根據企業的具體業務問題和需求,針對性的提供各行業大數據解決方案。
spark機器學習基礎統計學知識
來源:未知 時間:2018-08-14 瀏覽次數:159次
一、矩陣與向量
1.矩陣:按長方陣列排列的實數或復數的集合,在程序中以二位數組存儲,矩陣的運算包括(加,減,乘(數乘,叉乘),轉置,共軛)
scala中創建矩陣(使用breeze包,mllib中的包創建的矩陣無法做計算)
val jz1 = breeze.linalg.DenseMatrix(Array(1,2,3),Array(4,5,6))
2.向量:既有大小又有方向的量稱為向量,矩陣中每一個列可以看做是一個列向量,每一行可以看做是一個行向量,向量的模長看做是向量的大小
向量的N范數為向量內每個元素的N次方和開N次方,P等于2時范數為向量的摸長

scala中創建向量(使用breeze包,mllib中的包創建的向量無法做計算)
var xl1 = breeze.linalg.DenseVector(1,2,3,4) 加法xl1+xl1
二、統計學基礎
1.平均數(數學期望是抽樣的平均數)

2.方差衡量一組數據的離散率

3.眾數:是一組數據中出現次數最多的數數值,可以是0個或多個
1,2,3,4無眾數
2, 2, 3,4, 5,眾數為2
3,4,5,3,5眾數為3和5
4.中位數:為一組數據按大小排序后最中間的那個數(這組數據為偶數時取中間兩個值得平均值)
5.scala中使用stat.Statistics.colStats()
6.皮爾遜相關系數:體現兩個變量X,Y線性相關性的系數,
stat.Statistics.corr(x,y) //x,y為集合或行向量
7.假設檢驗(皮爾森卡方檢驗),先提出假設,然后統計驗證這種假設是否能被拒絕
stat.Statistics.chiSqTest(matrix) //參數為矩陣數據
eg :
男 女
右撇子 127 147
左撇子 19 10
假設性別與左右撇子兩個事件相互獨立,matrix = |127 147 |
|19 10 |
三、基礎算法
回歸算法與分類算法類似,區別是回歸是線性的分類是離散的
將所有輸入分布出來,擬合一條個函數表示這種分布(擬合的過程較訓練),根據這個函數的輸入求得輸出就是回歸

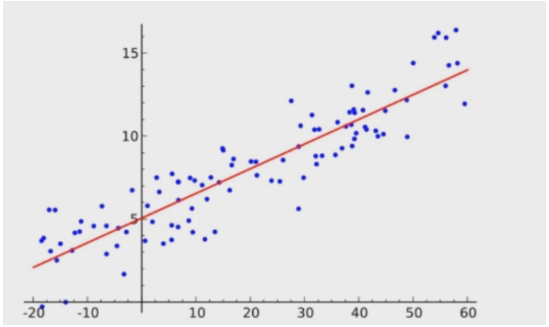
1.線性回歸:在回歸分析中,自變量與應變量基本滿足線性關系就可以用線性模型進行擬合
只有一個自變量叫一元線性回歸,自變量與應變量之間的關系可以用一條直線表示
多個自變量的叫多遠線性回歸,自變量與應變量之間的關系可以用一個平面或者超平面表示
線性回歸的前提條件
A.自變量與應變量之間有線性趨勢(皮爾遜相關系數)
B.自變量之間沒有關聯
對于統計學習來講機器學習模型就是一個函數表達式,其訓練過程就是不斷更新這個函數式的參
數,以便這個函數能夠多未知數據產生最好的預測結果
線性回歸的數學表達式
y=ax+b
y=Wt*X ,常用,其中W,X為列向量,Wt為W轉置,
2.最小二乘法:通過最小化殘差平方和(數據點與它在回歸直線上相應位置的差異稱為殘差)來找到最佳的函數配比,導數的意義是函數曲線的斜率


- 上一篇: spark機器學習開發之scala函數及基礎語法
- 下一篇: 大數據經典案例分析