 掃一掃
掃一掃
服務近2000家企業,依托一系列實踐中打磨過的技術和產品,根據企業的具體業務問題和需求,針對性的提供各行業大數據解決方案。
PDF及圖片資源內容識別與智能歸檔系統解決方案
來源:未知 時間:2018-21-7 瀏覽次數:224次
1.1.1 資源加工處理
資源元數據 :即PDF 文件的 基本信息:標題 作者、關鍵詞、摘要、時間等數據項。1.1.1.1 資源加工大體功能
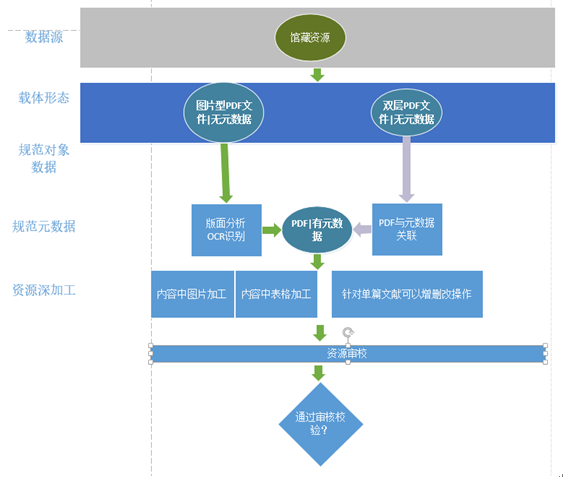
圖資源加工模塊
加工大體流程是:
1、 根據資源目錄選擇PDF文件建立 PDF版面模板,并管理
1、2、根據資源目錄篩選未加工的PDF文件,關聯一對應批次的版面模板,OCR自動提取標題、摘要、作者等、可人工二次編輯。
1、3、審核人員針對已加工的文獻進行審核不通過駁回重新加工,通過發布。
文件狀態有:知識的加工狀態(未加工、加工中、待審核、審核通過狀態)
Ø 數據源
數據源 主要為 外文pdf文件(圖片型PDF和 雙層PDF文件)。
Ø 載體形態
從資源的載體形式劃分為如下五種情況:tif文件類(來源文獻搶救)、pdf文件類型、帶元數據的pdf、無原文的文摘數據、網頁數據。
Ø 資源元數據加工
對元數據進行數據提取和數據規范。對單層的pdf進行基本元數據加工,包括數據標題、摘要、作者、關鍵詞、時間等信息的提取。
版面分析:對同類資源的pdf文件,進行版面格式化分析,人工標注標題、摘要、作者等版面區域,對區域內的文字內容進行識別,錄入到相應的元數據字段中。
掃描紙質文獻:利用掃描儀對期刊等紙質文獻進行掃描,掃描儀支持OCR識別,形成雙層PDF文件。
PDF與元數據的關聯:通過掃描儀加工的文獻,進行版面分析后,把加工的對象數據與元數據進行管理。
OCR識別:對圖片中的文字內容進行識別。
Ø 資源深加工
包括圖表加工和引文加工。
Ø 資源組織
對各類不同來源的資源進行重新組織和知識關聯
1.1.1.2 功能設計
1.1.1.2.1 版面分析
根據數字化加工要求,資源采用流水線式的數字化加工流程,將紙質資源、資料轉為圖像信息的電子資源。主要包括資源提檔、資源整理、數據錄入、批量掃描、圖像編輯、資源校核、資源歸還等多道工序,構成一個完整的流水線加工流程,并支持工序回饋,形成一個閉環的質量監控系統。1.1.1.2.1.1 模板定制
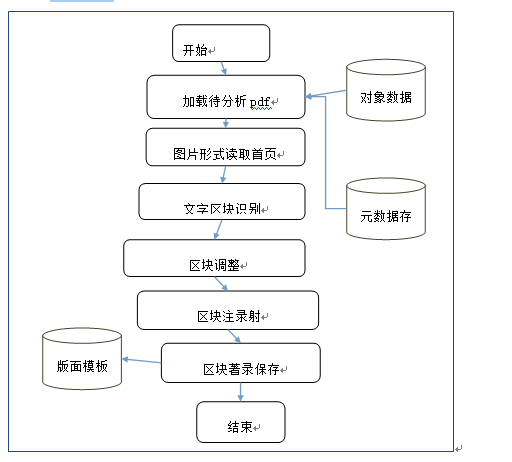
圖模塊定制流程圖
加載待分析pdf:從文獻庫中提取待加工的數據一條。
圖片形式讀取首頁:以圖片形式,讀取pdf首頁,首頁一般情況包含了標題、摘要、作者信息。
文字區塊識別:通過OCR技術,對圖片的文字區域進行區塊識別。

區塊調整:自定識別的區間,不具備一般性,需要人工進行調節,圈定區域。
區塊注錄映射:對識別的區域進行元數據項映射,如:把圖中的第二塊區域映射到標題,第五塊區域映射到英文標題。
區塊注錄保存:把映射的區域塊坐標和映射的元數據項信息保存到版面模板庫中。
1.1.1.2.1.2 模板管理
對模板進行管理,包括模板預覽、模板詳情、模板編輯功能。Ø 區塊信息數據項
| 區塊信息 | 描述 |
| 區塊ID | 區域塊唯一標識 |
| 頂坐標 | |
| 底坐標 | |
| 左坐標 | |
| 右坐標 |
Ø 區塊信息-元數據數據項映射
| 映射 | 描述 |
| 區塊ID | 區域塊唯一標識 |
| 元數據名稱 |
元數據項規范名稱,本系統映射的元數據項包括: 標題 摘要 作者 發表時間 正文區域 |
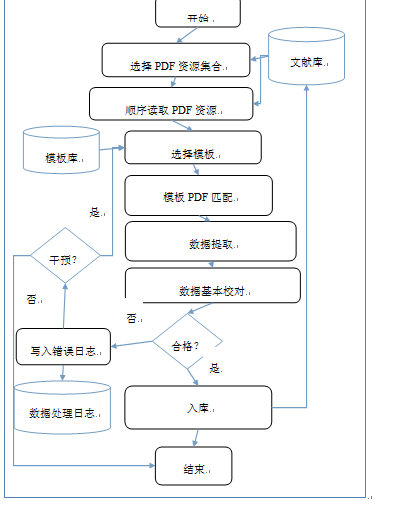
1.1.1.2.1.3 模板匹配
圖模塊匹配流程圖
1.1.1.2.1.4 摘要提取
基于OCR內容識別后,對摘要信息的識別,摘要具有在正文獨立成章節的特點,如:Abstract:XXXX的特征。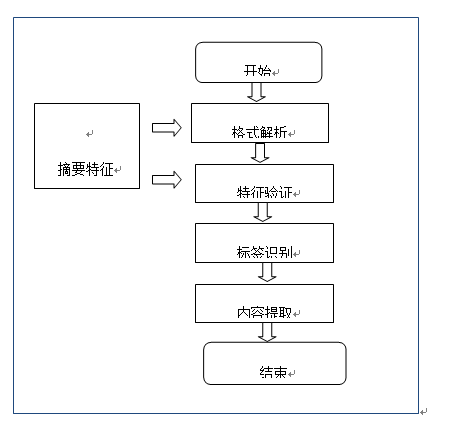
圖摘要提取流程圖
1.1.1.2.2 圖表加工
圖表加工包括對PDF文獻內容中的圖像和表格提取出來 ,針對每一個添加標題、標簽詞數據項。1.1.1.2.2.1 圖表元數據提取
利用圖標的標簽,進行圖標提取。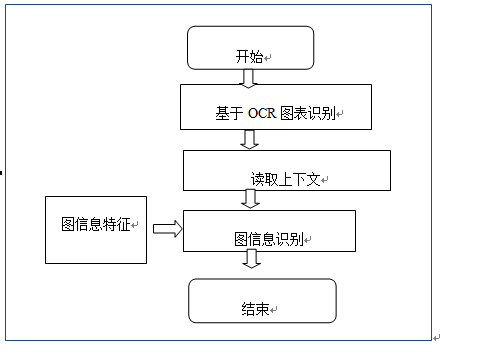
圖圖表元數據提取流程圖
1.1.1.2.2.2 圖表管理
對文檔中的抽取的圖標進行管理。術語信息如下:| 項目名稱 | 說明 |
| 圖表名稱 | 從文檔中抽取的圖表名稱 |
| 圖片標簽 | 加工人員提取或用戶建議 |
| 圖片信息 |
規格信息 圖表大小 格式:jpg 圖表類型 |
| 來源文獻 | 所屬文獻 |
圖片建議標簽管理
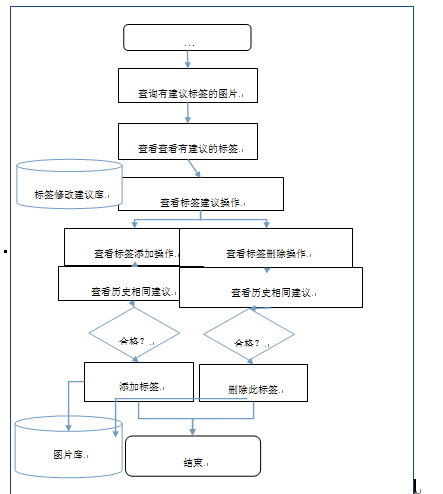
圖圖表管理流程圖
1.1.1.2.3 數據校驗
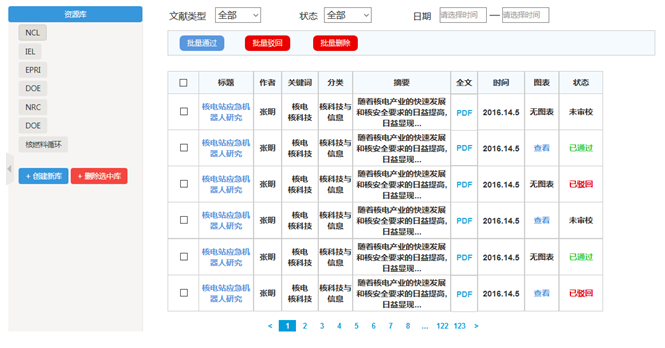
加工人員可以通過加工反饋,查看審核人員對自己加工知識的意見。為了更好的跟蹤一條知識的狀態,查看此知識在整個加工流程中所處的位置,可點擊知識加工狀態,可以查看知識的加工狀態(未加工、加工中、待審核、審核通過狀態)。1.1.1.3 大體模塊原型如下截圖所示:

 |
PDF及圖片資源內容識別與智能歸檔系統解決方案 |
- 上一篇: 旅游景點及園藝展會游客大數據分析與應用支撐平臺解決方案
- 下一篇: 工會幫扶工作管理系統解決方案