 掃一掃
掃一掃
服務近2000家企業,依托一系列實踐中打磨過的技術和產品,根據企業的具體業務問題和需求,針對性的提供各行業大數據解決方案。
研報智能審核系統技術方案-證券
來源:未知 時間:2022-51-30 瀏覽次數:206次
一,需求背景在當前監管機構大力推動金融行業數字化、智能化的背景下,針對研報產出流程中大量繁雜底稿的整理、傳統審核流程等作業方式,智能核查系統從以下幾個方面實現資源整合、信息共享、業務協同,以達到相關部門人員提升工作效率、提高產出質量等效果。
從業務流程角度來看,研究員整理底稿,撰寫研究報告,提交給核查人員后,核查人員對研究報告進行審核,期間伴隨打回或傳給下一位審核人員的動作,直至審核通過,流程無法規范化,信息很難共享。核查系統中可以支持管理人員制定審核流程,整個過程線上化,相關人員可實時關注項目進展,關鍵節點數據共享,減少信息傳遞阻礙。
從審核本身來看,核查人員需要在繁雜的底稿中一一對應每一個數據出處,且需要花費大量時間通過查詢第三方數據來確保數據準確,核對過程沒有數據沉淀,通過線下方式效率低、易出錯。核查系統可將文檔通過技術手段線上化后,對文檔內容進行分析,智能判斷文檔中的數據與相關公開數據一致性,自動關聯相關底稿內容,確保研究報告與相關底稿內容的一致性,通過語義分析等技術校驗確保文本規范性,另外文檔數據沉淀后,支持底稿溯源。核查系統應通過相關技術提供一套完整的文檔核查能力,解決核查人員對于核查過程中的痛點。
1.軟件系統開發目標
從業務流程出發,系統應達到對業務流程完成覆蓋,有相應的流程管理、人員管理、權限管理、核查內容管理,提高工作效率,規范核查流程。
對于底稿,系統應具備底稿管理能力,完成數據沉淀,提供溯源能力,包括文本段落、數值等。
對于核查本身,系統提供研究報告上下文一致性審核,底稿一致性審核,外部數據核對,文本規范性審核能力。
2.總體方案
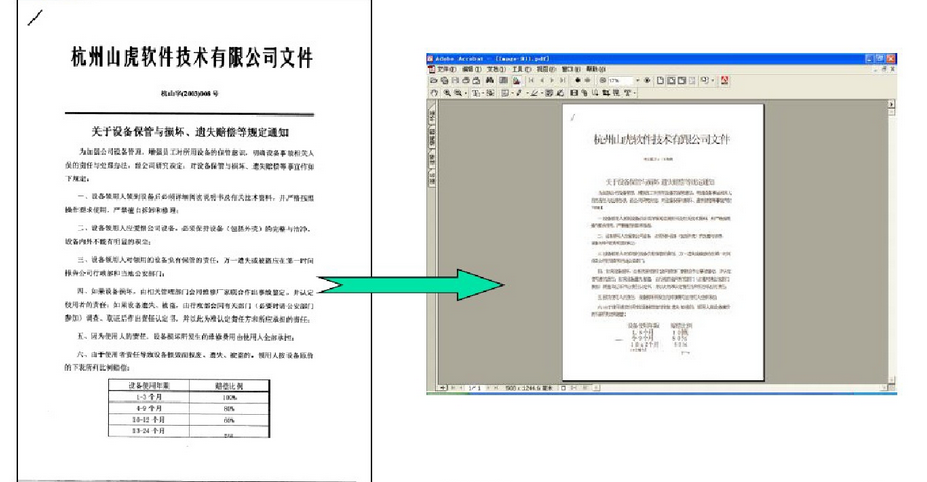
整個系統圍繞業務內容進行設計,從數據來源、系統核心處理流程以及數據落地存儲幾個方面進行考慮。通過將業務人員上傳的文件進行OCR、NLP、智能語言處理技術解析并結構化存儲,完成核查對象的數據處理,對接第三方數據源數據,分析并清洗后得到外部數據支持。
搭建工作流引擎支撐業務流程配置,包括人員權限相關管理、核查流程和相關內容管理,對研究人員、審核人員間的工作流程完成覆蓋,支持文件上傳、底稿管理、智能審核、人工審核、批注、反饋消息通知等功能,達到過程可追溯,提高流程規范,確保輸出研究報告的質量。
對于核心核查功能,整合已解析并結構化的文檔,關聯已處理的第三方數據,依賴配置的業務流程及核查相關規則要求,系統自動對研究報告進行上下文一致性的審核,研究報告與底稿間一致性審核,文中數據與第三方數據一致性,文本內容規范性審核。
結構化存儲各類文檔數據,結合搜索引擎,達到底稿溯源能力,支持業務人員在系統中通過簡單的關鍵字信息在海量底稿文檔中篩選關鍵文檔。
系統設計上,結構清晰,操作交互簡便,使用流程清晰易用,理解與學習成本底
二.技術實現方案
1.服務端文件管理
文件管理模塊是該系統的核心,由文件表格、文件樹和文件編輯模塊三個插件構成。主要功能可以分為:
1)基于Web的文件資源瀏覽。
2)基于Web的文件在線打開。
3)基于HTYP協議的大文件傳輸。
4)大文件傳輸的斷點續傳功能。
5)用戶文件的空間管理。
2.數據庫及文件服務器
本系統使用MySQL數據庫,用來保存用戶信息、上傳的文件基本信息。文件斷點續傳模塊采用base54加密的存儲技術來實現對文件信息的管理。
3.OCR智能識別
圖像處理:去噪聲、平滑、去黑邊、傾斜校正等。

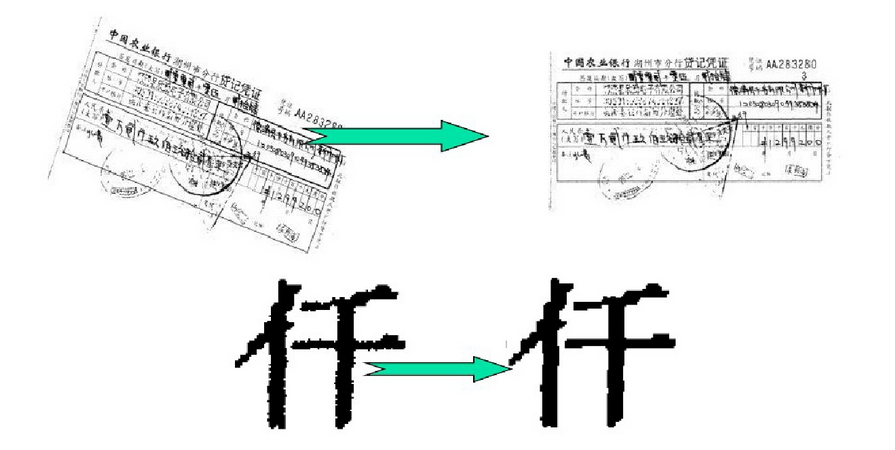
表格識別

字符分割

字符識別

格式化輸出
4.語義識別
姓名信息提取:精準提取文本填單信息中收件人或寄件人的名稱,并輸出結構化信息
電話信息提取:精準提取文本填單信息中寄件人或收件人的聯系方式,并輸出結構化信息
詞性標注:為自然語言文本中的每個詞匯賦予一個詞性,例如名詞、動詞、形容詞等
命名實體識別:識別自然語言文本中具有特定意義的實體,主要包括人名、地名、機構名、時間日期
短文本相似聚合:通過語義相似度計算,判斷兩個短文本的語義表述是否相近,從而實現相似短文本的聚合或去重
文本可計算:詞表中所有的詞向量構成一個向量空間,每一個詞都是這個詞向量空間中的一個點,利用這種方法,實現文本的可計算
領先技術應用:詞義相似度是自然語言處理中的重要基礎技術,是專名挖掘、query改寫、詞性標注等常用技術的基礎之一
算法識別準確:在大規模人工標注的數據基礎上,句法結構描述體系簡潔通用,海量數據訓練讓文本匹配更準確
5.智能報告知識庫地址識別
地址信息提取:精準提取文本填單中的地址信息,并按省、市、區、街道、詳細地址的格式結構化輸出姓名信息提取:精準提取文本填單信息中收件人或寄件人的名稱,并輸出結構化信息
電話信息提取:精準提取文本填單信息中寄件人或收件人的聯系方式,并輸出結構化信息
詞法分析
中文分詞:將連續的自然語言文本,切分成具有語義合理性和完整性的詞匯序列詞性標注:為自然語言文本中的每個詞匯賦予一個詞性,例如名詞、動詞、形容詞等
命名實體識別:識別自然語言文本中具有特定意義的實體,主要包括人名、地名、機構名、時間日期
短文本相似度
短文本相似度計算:提供兩個短文本之間的語義相似度計算能力,輸出的相似度是一個介于0到1之間的實數值,輸出數值越大,則代表語義相似程度相對越高短文本相似聚合:通過語義相似度計算,判斷兩個短文本的語義表述是否相近,從而實現相似短文本的聚合或去重
文本糾錯
文本糾錯能力:準確識別出文本中出現的字詞或標點錯誤,并針對性給出正確的建議文本內容,在搜索引擎、語音識別、內容審核等場景有廣泛應用詞向量表示
詞語向量化:通過訓練的方法,將語言詞表中的詞映射成一個長度固定的向量文本可計算:詞表中所有的詞向量構成一個向量空間,每一個詞都是這個詞向量空間中的一個點,利用這種方法,實現文本的可計算
詞義相似度
深度語義解析:該技術常用于計算兩個給定詞語的語義相似度,基于自然語言中的分布假設,即越是經常共同出現的詞之間的相似度越高領先技術應用:詞義相似度是自然語言處理中的重要基礎技術,是專名挖掘、query改寫、詞性標注等常用技術的基礎之一
依存句法分析
深度語義結構:利用句子中詞與詞之間的依存關系來表示詞語的句法結構信息(如主謂、動賓、定中等結構關系) ,并用樹狀結構來表示整句的的結構(如主謂賓、定狀補)等算法識別準確:在大規模人工標注的數據基礎上,句法結構描述體系簡潔通用,海量數據訓練讓文本匹配更準確
DNN語言模型
基于條件概率:該技術通過計算給定詞組成的句子的概率,從而判斷所組成的句子是否符合客觀語言表達習慣系統結構
知識庫管理系統由如下四部分就組成:知識庫使用關系型數據庫來存放知識,包括事實與規則。
搜索模塊實現知識庫和推理機之間的知識搜索和與傳遞。
查詢模塊實現推理機對知識庫的知識查詢。
一致性、完整性檢查模塊在知識庫中的知識發生變動時對知識庫中的知識進行一致性、完整性檢查。
功能概述
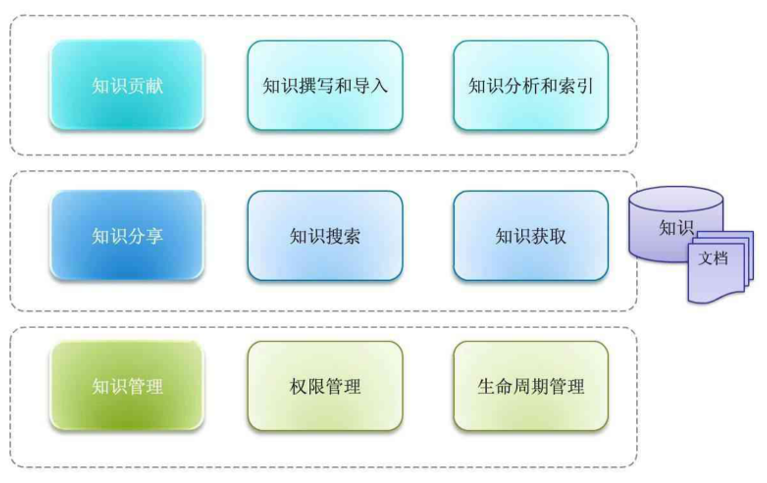
搭建海量文檔集中存儲的平臺,實現統一的文檔管理。對文檔進行統一管理可支持顯示、搜索、排序等功能。提供權限控制機制,針對用戶進行細粒度的權限控制,控制用戶的管理、瀏覽、閱讀、編輯、下載、刪除、打印、訂閱等操作,實現文檔安全共享。采用加密存儲,防止文件擴散,全面保證數據的安全性和可靠性。
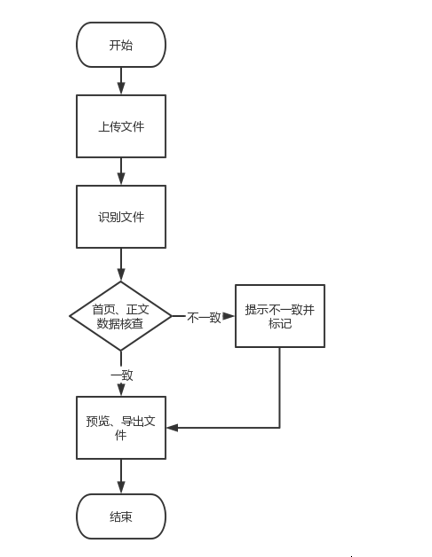
6.底稿審核
登錄系統上傳文件,系統將自動識別文件內容,區分首頁及正文頁,對首頁數據進行整理,將整理的數據在文檔正文內進行一致性核查,核查通過則提示驗證通過,否則提示不通過。
7.文檔協同
權限管理
通過集中的數據權限管控,分別對不同安全等級的數據分配不同的訪問權限,并基于統一的安全技術框架與多維度的安全控制模型, 對用戶授權及數據訪問權限進行校驗,保證核心數據的保密性。系統權限機制:系統權限模塊使用自定義用戶角色機制;
自定義用戶角色:管理員可創建用戶角色組,并設置角色組名稱;
自定義權限:針對不同的角色組設置不同的權限;
自定義用戶:創建用戶賬戶并加入到不同的角色組(用戶權限設置)。
操作流程簡述:創建角色-選擇功能模塊—>添加管理員-將管理員添加到該角色(管理員獲得該角色權限)、編輯角色權限后對應管理員權限相應改變(需注銷登錄)。
文檔在線操作
實現流程
對所有用戶進行統一管理,提供對外注冊(前端把用戶填寫的用戶名、密碼、手機號等信息加密后發送給服務端;服務端拿到數據,再和生成的唯一用戶ID一起,存入表中。)、登錄接口(前端要求用戶輸入用戶名+密碼并發送給服務端,服務端校驗用戶名和密碼的正確性;校驗通過后,根據「用戶名+密碼+密鑰+時間戳」生成有時效性的Token,返回給客戶端;登錄之后前端所有請求都帶著Token信息。服務端根據Token獲取當前登錄用戶信息并判斷請求是否合法。)、對文檔進行統一管理,其中包括創建文檔(前端發送文檔名稱、文檔內容給服務端;服務端生成唯一的文檔ID,從Token中獲取到用戶ID,獲取服務器時間然后把數據一起存入數據庫中;服務端返回文檔ID給前端),修改文檔(為了及時保存用戶編輯的內容,需要在用戶編輯過程中實時把數據傳遞給服務端。前端生成修改數據發送給服務端;服務端從數據庫中獲取文檔內容,然后根據用戶的行為合并操作,最后保存到數據庫中。),查看文檔(前端發送要查看的文檔ID給服務端;服務端根據文檔ID返回文檔內容),刪除文檔(前端發送要刪除的文檔ID給服務端;服務端根據文檔ID刪除對應文檔)等。自定義表單
自定義表單可分為表單定義管理部分、表單呈現/提交部分、表單數據查看/管理部分。表單定義管理
表單基本信息管理(表單名稱、描述)、表單存儲表字段管理、表單布局設計、表單數據驗證定義、表單字段關聯/子表單管理、表單字段編輯框行為管理。表單存儲表字段定義
定義表單中用到的數據項,包括字段名、字段類型、長度、默認值、編輯框類型、是否允許為空、是否自增長字段、分組名稱、是否在列表中顯示等信息。編輯框類型一般有:文本框、文本域、復選框、單選框、列表框、時間日期選擇、文件上傳框等。表單布局設計
表單模板,表單中的數據項說明、編輯框、數據驗證用內部變量來代替,系統可提供自動生成表單的功能,用戶也可以自己手工修改。表單數據驗證定義
定義需要驗證字段的規則,驗證規則,用正則表達式的方式定義。表單字段關聯/子表單管理
定義表/表單之間的關聯信息,即主鍵外鍵信息。表單字段編輯框行為定義
主要負責處理字段值發生變化時引發的其他編輯框事件,比如連動下拉框、從選擇值中返回值并賦予其他字段編輯框、其他編輯框的隱藏等。表單運行時呈現及提交
根據表單定義的布局及其他設置呈現表單,并一起生成驗證、行為用到的JS代碼。如果填寫表單時,先填主表信息,然后填寫從表信息,多個表單之間要進行跳轉,保存的臨時表單值可采用SESSION進行傳遞,最后一起提交,提交時先寫入主表信息,并返回主鍵值(如果存在主從表的話),然后寫從表數據。表單數據管理
根據字段配置信息顯示表單的數據列表,并進行管理。- 上一篇: 秒懂列式數據庫和行式數據庫
- 下一篇: 大數據ETL技術方案